Webscraping Airbnb with scrapy
Feb 26, 2016
Note 24/03/2017: The tutorial at the time of writing does not work from all locations and frequent airbnb updates to its website make it difficult to maintain. The concepts introduced here with some modifications are still valuable in getting you started. In any case I wish luck with scraping!*
The web is full of wonderful and freely available information. Some of it is readily available and neatly organized (see this repo) and some of it is hiding in plain sight. I am speaking about unstructured data on websites, which has either never been organized or the owner does not offer easy access and thus sits there locked away in dusty HTML files. Some of this wealth of data I am speaking about is publicly available and comes from state of the art databases, but there is no easy way to access it, such as airbnb.com. The listings on the Airbnb are freely accessible to anyone who cares to brows their really nice portal, but if we wanted to do some exploratory statistical analysis then there is no easy way to get a complete and sufficiently large dataset. This is where web scraping comes in.
I have always had some questions I wanted to ask airbnb, for example:
- How many of their listings are there in my city? (if you check a simple search will never list more than 300 results at a time)
- What is the price distribution?
- Do lots of people leave reviews?
- Is it true that most reviews are positive?
I am sure that you can come up with your own set of questions you would like to tickle out of such data. So here I walk you through how to get some of the data, to answer some of these questions.
You can find the complete code here as github repo, feel free to fork, clone or do whatever you want with it.
The Plan
First we are going to set up the environment to get scrapy to work, then write some python code to get our spider to do the tedious task of scraping and after all is said and done we are going explore our hard won dataset.
Setting up the system
I assume that you have some basic python programming skills and are not intimidate by the command line. We are going to use the python scraping library scrapy to do the heavy lifting of routing, scheduling and processing requests.
To install scrapy follow their setup guide for your system, note that scrapy is not compatible with python 3 so make sure that you are using 2.7. Even better if you plan on doing more work in python, and trust me you will, then you should install the great scientific python bundle Anaconda.
Once you are set up, it is time to test drive scrapy. Open a terminal and type:
scrapy shell http://www.google.com
If this does not result in any errors and you are in the scrapy shell then you are up and running.
Now we set up our project, the scrapy cli interface fortunately creates the basic scaffolding. Navigate using the terminal where you want to save your project, and execute the following commands.
cd /path/to/your/location
scrapy startproject bnbtutorial # generate the scrapy scaffolding
cd bnbtutorial # change into directory
scrapy genspider bnbspider airbnb.com # generate a base spider
This is the basic setup in the next section we will write the logic of the spider and define what we want it to scrape.
Getting started with Scrapy
Your project folder should look like this:
.
├── bnbtutorial
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── bnbspider.py
└── scrapy.cfg
Open the bnbspider.py in your favourite editor (e.g. pycharm)
# -*- coding: utf-8 -*-
import scrapy
class BnbspiderSpider(scrapy.Spider):
name = "bnbspider"
allowed_domains = ["airbnb.com"]
start_urls = (
'https://www.airbnb.com/',
)
def parse(self, response):
pass
Your code will look like this. Every spider class needs to implement the method parse which takes as argument a http response object from the page(s) found in start_urls, which we are going to process further. Before we go into the actual data extraction phase we need to get some information from a potential results page. If we run a query and obtain a list of results we want to know how many pages there are. To do this, we add the following method to our BnbspiderSpider class.
def last_pagenumer_in_search(self, response):
try: # to get the last page number
last_page_number = int(response
.xpath('//ul[@class="list-unstyled"]/li[last()-1]/a/@href')
.extract()[0]
.split('page=')[1]
)
return last_page_number
except IndexError: # if there is no page number
# get the reason from the page
reason = response.xpath('//p[@class="text-lead"]/text()').extract()
# and if it contains the key words set last page equal to 0
if reason and ('find any results that matched your criteria' in reason[0]):
logging.log(logging.DEBUG, 'No results on page' + response.url)
return 0
else:
# otherwise we can conclude that the page
# has results but that there is only one page.
return 1
This function extracts from a results page the last page number using xpath queries. If you are not familiar with xpath, look at the w3 tutorial.
With this information we can then create a list of pages using the following format to go from one page to the next.
https://www.airbnb.com/s/Lucca--Italy?page=<page_number>
Add the following lines to bnbspider.py
def parse(self, response):
# ge the last page number on the page
last_page_number = self.last_pagenumer_in_search(response)
if last_page_number < 1:
# abort the search if there are no results
return
else:
# otherwise loop over all pages and scrape!
page_urls = [response.url + "?page=" + str(pageNumber)
for pageNumber in range(1, last_page_number + 1)]
for page_url in page_urls:
yield scrapy.Request(page_url,
callback=self.parse_listing_results_page)
Before we can move to the data extraction phase, we need to get the unique listings url from the results page using the following method.
def parse_listing_results_page(self, response):
for href in response.xpath('//a[@class="media-photo media-cover"]/@href').extract():
# get all href of the speficied kind and join them to be a valid url
url = response.urljoin(href)
# request the url and pass the response to final listings parsing function
yield scrapy.Request(url, callback=self.parse_listing_contents)
Now to the interesting part, extracting the data. I have writte the xpath to extract some of the data from the page which in this case is hidden in a jsonfile. This is a minimal example and there is a lot more information, to get (i.e. geographic coordinates). The scrapy documentation has a nice primer on how to use the developer tools found in Firefox/Chrome to create xpath expressions and some other general tips.
Thi is the centrepiece of the class, the function which extracts the data and stores it in a scrapy object, which we are going to define shortely.
def parse_listing_contents(self, response):
item = BnbtutorialItem()
json_array = response.xpath('//meta[@id="_bootstrap-room_options"]/@content').extract()
if json_array:
airbnb_json_all = json.loads(json_array[0])
airbnb_json = airbnb_json_all['airEventData']
item['rev_count'] = airbnb_json['visible_review_count']
item['amenities'] = airbnb_json['amenities']
item['host_id'] = airbnb_json_all['hostId']
item['hosting_id'] = airbnb_json['hosting_id']
item['room_type'] = airbnb_json['room_type']
item['price'] = airbnb_json['price']
item['bed_type'] = airbnb_json['bed_type']
item['person_capacity'] = airbnb_json['person_capacity']
item['cancel_policy'] = airbnb_json['cancel_policy']
item['rating_communication'] = airbnb_json['communication_rating']
item['rating_cleanliness'] = airbnb_json['cleanliness_rating']
item['rating_checkin'] = airbnb_json['checkin_rating']
item['satisfaction_guest'] = airbnb_json['guest_satisfaction_overall']
item['instant_book'] = airbnb_json['instant_book_possible']
item['accuracy_rating'] = airbnb_json['accuracy_rating']
item['response_time'] = airbnb_json['response_time_shown']
item['response_rate'] = airbnb_json['response_rate_shown']
item['nightly_price'] = airbnb_json_all['nightly_price']
item['url'] = response.url
yield item
note that this function uses the json library so be sure to import it import json.
Now to the last step, we need to define a scrapy.Item class, to store the scraped info to. Open the file items.py and create all the fields which we are going to need.
import scrapy
class BnbtutorialItem(scrapy.Item):
rev_count = scrapy.Field()
amenities = scrapy.Field()
host_id = scrapy.Field()
hosting_id = scrapy.Field()
room_type = scrapy.Field()
price = scrapy.Field()
bed_type = scrapy.Field()
person_capacity = scrapy.Field()
cancel_policy = scrapy.Field()
rating_communication = scrapy.Field()
rating_cleanliness = scrapy.Field()
rating_checkin = scrapy.Field()
satisfaction_guest = scrapy.Field()
instant_book = scrapy.Field()
accuracy_rating = scrapy.Field()
response_time = scrapy.Field()
response_rate = scrapy.Field()
nightly_price = scrapy.Field()
url = scrapy.Field()
Be sure to import BnbtutorialItem in the BnbSpider, by adding from bnbtutorial.items import BnbtutorialItem to the top of of the bnbspider.py file, as well as adding to the function parse_listing_contents at the beginning item = BnbtutorialItem(). After these changes the spider script should look something like this,
# -*- coding: utf-8 -*-
import scrapy
from bnbtutorial.items import BnbtutorialItem # <--- import here!
QUERY = 'Lucca--Italy'
class BnbSpider(scrapy.Spider):
name = "bnbspider"
# .....
# LEFT OUT SOME CODE SAME AS IN THE PREVIOUS PART
# .....
def parse_listing_contents(self, response):
item = BnbtutorialItem() # <--- user the Item here!
json_array = response.xpath('//meta[@id="_bootstrap-room_options"]/@content').extract()
# ....
# REST OF FILE AS BEFORE
Run the Query
Now to run your own query for your city simply edit the variable QUERY at the top of the script, which takes most often the following form City--Country a quick check by running the query on airbnb will reveal.
As good netizens there are a few things we need to keep in mind when scraping a website. As far I know it isn’t illegal to scrap a website, starting a DDoS attack on the other hand is, so to avoid any ambiguity in what you are doing, you should throttle the speed at which you scrape. For Airbnb I have found that it is best not to go above the limit of 8 pages per minute, or your IP will be banned. To enable the throttling in scrapy you need to uncomment the following lines in settings.py . If you need more speed, you might want to look into renting some amazon AWS machines (micro instances are pretty cheap).
USER_AGENT = 'bnbtutorial (+http://www.yourdomain.com)'
CONCURRENT_REQUESTS_PER_DOMAIN=10
AUTOTHROTTLE_ENABLED=True
# The initial download delay
AUTOTHROTTLE_START_DELAY=5
# The maximum download delay to be set in case of high latencies
AUTOTHROTTLE_MAX_DELAY=60
# Enable showing throttling stats for every response received:
AUTOTHROTTLE_DEBUG=False
And now for the main event, running the spider and see how it all works (hopefully). Run the following command inside your scrapy project and see the data flow in.
scrapy crawl bnbspider -o LuccaAirbnb.csv
As I have already anticipated earlier this is a very basic spider to crawl airbnb. You will see that it will never return more than 300 results at a time and that some records will be duplicates. It is then left to you to find ways to circumvent this limit and avoid calls to urls that have already been scraped (hint: use filters to fine-grain your queries and look at the scrapy documentation on how to avoid duplicate requests.)
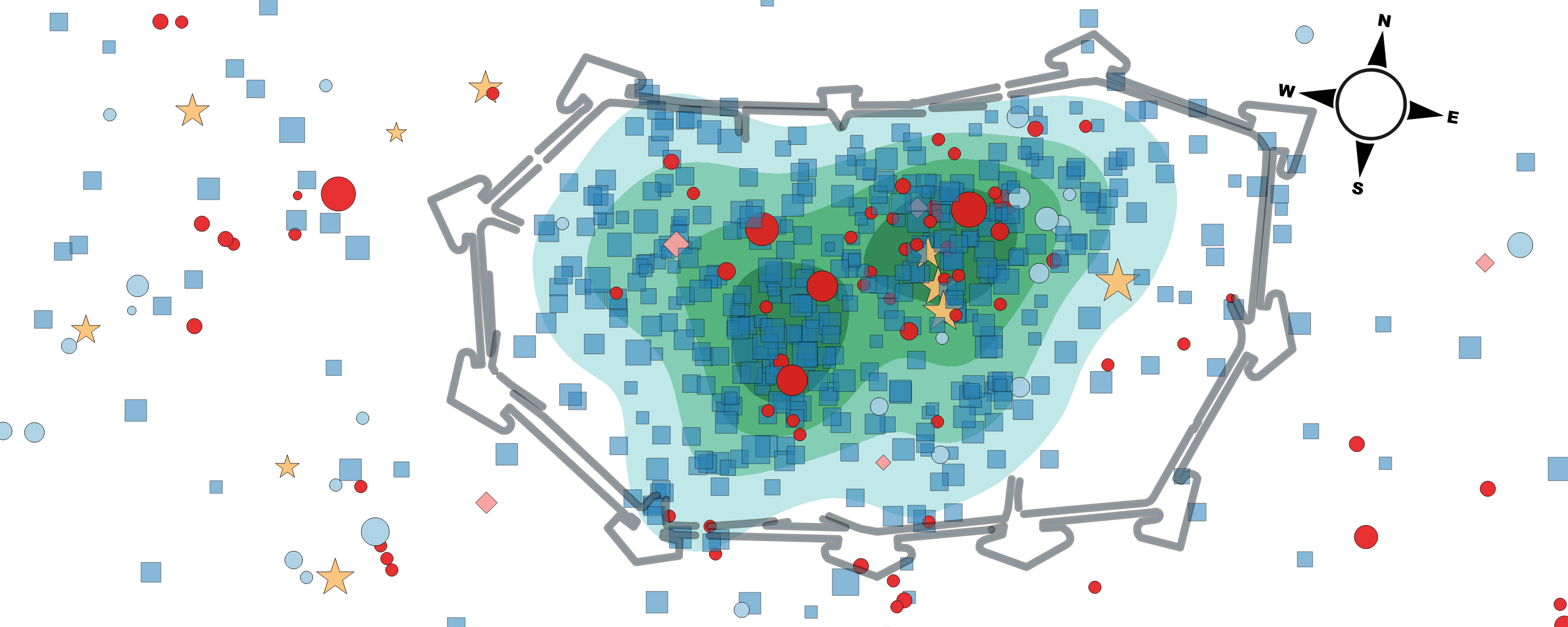
Plot the Data on a Map
The listings contain also longitude and latitude information (which we did not get here, but you can get it easily if you have a look at the head of any listings page).
We can use this data to visualize the distribution and concentration of properties on a map.
Issues with code
If you have problems with the code please open an Issue on Github. Talking about code there is a lot easier, thanks ;). here is the Issues page
Common Problems
If your script runs but you do not get any results, then it could be that airbnb redirects you to a country specific domain. For example, you are in the uk and you are redirected from airbnb.com -> airbnb.co.uk.
Since in the above code I have set allowed_domains = ["airbnb.com"] to only contain airbnb.com the spider would refuse to go on any other domain.
A workaround is to either remove this line and let the spider roam free, or you add your domain to it, e.g allowed_domains = ["airbnb.com", "airbnb.co.uk"].
Edit
- added instructions on how to change city in the query
- updated xpath so it works with the new layout of airbn - 24/06/16
- changed
'//div[@class="listing"]/@data-url'to'//a[@class="media-photo media-cover"]/@href'